Dieser Post bezieht sich wieder auf ein FileMaker-Problem, das ich letztens hatte. Wie kann man mehrere Tabellen einer FileMaker-Anwendung in eine Datei exportieren und in eine andere Instanz derselben Datenbank wieder importieren? Wir haben nicht alle die Lust oder das Kleingeld, eine Server-Anwendung zu entwickeln und zu betreiben und müssen uns gelegentlich mit dem Abgleich mehrerer Instanzen „zu Fuß“ begnügen. Das kann auch prima funktionieren, wenn stets klar geregelt ist (und das auch alle Beteiligten verinnerlicht haben), wer jeweils der „Master“ ist, wer jeweils die Datenhoheit besitzt.
Nun kann man mit FileMaker prima einzelne Tabellen oder Auszüge davon exportieren und auch wieder importieren, aber das bezieht stets auf nur eine Tabelle. Insbesondere der Export erzeugt dann für jede Tabelle eine eigene Datei. Das ist hässlich. Wie kann nun der Export von mehreren Tabellen in eine einzige Datei realisiert werden?
In einigen FileMaker-Foren wurde schon der Vorschlag gemacht, doch die ganze FileMaker-Datenbank als Kopie zu speichern und zu versenden. Das klingt doch recht brutal und ist sicher auch nicht in jedem Fall angemessen. Vielleicht sind in der Datenbank ja auch Tabellen, die aus Datenschutzgründen nicht versendet werden sollten. Ebenso kann es sein, dass nur der Auszug aus einer Tabelle verschickt werden soll. Ich finde die Idee nicht so gut und möchte sie hier verwerfen.
Eine andere Möglichkeit besteht darin, zwar jede Tabelle in eine eigene Datei zu exportieren, die resultierenden Dateien dann aber per AppleScript und zip zu einer Datei zusammenzufassen. Das geht auf dem Mac per AppleScript-Schritt auch ganz gut; bei Windows muss man aber doch ein paar mehr Verrenkungen anstellen (z.B. ein zip-Programm ausliefern und installieren und ein entsprechendes Shell-Script schreiben). In der Tat habe ich das in bisherigen Fällen so implementiert, aber richtig glücklich war ich damit nicht. Ich hatte stets das Gefühl, dass das doch auch mit FileMaker-Bordmitteln möglich sein sollte und bin dann auf die Lösung gekommen, die ich heute vorstellen möchte.
Kernidee ist hier die folgende: Wenn es schon nicht möglich ist, Tabellen in eine Datei zu exportieren, sollte man vielleicht lieber die Tabellen in eine (neue) Datei importieren. Und so wollen wir es auch anstellen. Grundlage ist unsere kleine Datenbank aus dem vorherigen Post, die zwei Tabellen „Erwachsene“ und „Kinder“ enthält (hier „Ex- und Import mehrerer Tabellen.fmp12“ genannt). Zusätzlich erzeugen wir eine weitere leere Datenbank „Transport.fmp12“. In dieser Datenbank schreiben wir ein kleines Script, das die gewünschten Tabellen importiert.
|
1 2 3 4 5 |
Datensätze importieren [ Quelle: “file:Ex- und Import mehrerer Tabellen.fmp12”; Ziel: “{Neue Tabelle}”; Methode: Hinzufügen; Zeichensatz: “Mac Roman”; Feldzuordnung: Quellfeld 1 importieren in Zielfeld 1 Quellfeld 2 importieren in Zielfeld 2 Quellfeld 3 importieren in Zielfeld 4 ] [ Ohne Dialogfeld ] Datensätze importieren [ Quelle: “file:Ex- und Import mehrerer Tabellen.fmp12”; Ziel: “{Neue Tabelle}”; Methode: Hinzufügen; Zeichensatz: “Mac Roman”; Feldzuordnung: Quellfeld 1 importieren in Zielfeld 1 Quellfeld 2 importieren in Zielfeld 2 Quellfeld 4 importieren in Zielfeld 5 ] [ Ohne Dialogfeld ] Variable setzen [ $Path; Wert:LiesAlsText ( Hole ( SystemDatum ) ) & "_" & Hole ( DateiName ) & ".fmp12" ] Kopie speichern unter [ “$Path” ] [ Kopie der aktuellen Datei ] Datei schließen [ Aktuelle Datei ] |
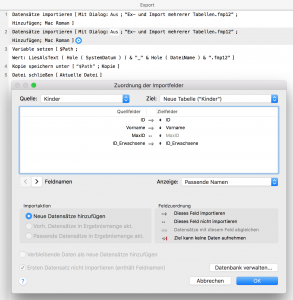 Das Script kopiert aus unserer Haupt-Datenbank die gewünschten Tabellen in neue eigene und speichert eine Kopie der Transport-DB (hier mit vorangestelltem aktuellen Datum) ab und schließt sich selbst. Simpel, nicht. In unserer Haupt-DB brauchen wir dann nur ein Script, das das Export-Script unserer Transport-DB anstößt:
Das Script kopiert aus unserer Haupt-Datenbank die gewünschten Tabellen in neue eigene und speichert eine Kopie der Transport-DB (hier mit vorangestelltem aktuellen Datum) ab und schließt sich selbst. Simpel, nicht. In unserer Haupt-DB brauchen wir dann nur ein Script, das das Export-Script unserer Transport-DB anstößt:
|
1 |
Script ausführen [ “Export” Aus Datei: “Transport” ] |
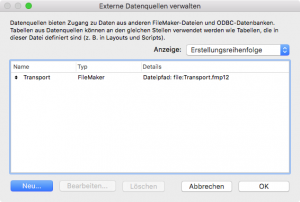 Dafür muss dort unsere Transport-DB als externe FileMaker-Datenquelle eingerichtet sein. Wir haben jetzt nur das Problem, dass in der Transport-DB stets neue Tabellen mit neuen Namen angelegt werden. Außerdem ist es hässlich, nun mit zwei Datenbanken zu arbeiten. Schöner wäre es doch, nur mit einer Datenbank auskommen zu können.
Dafür muss dort unsere Transport-DB als externe FileMaker-Datenquelle eingerichtet sein. Wir haben jetzt nur das Problem, dass in der Transport-DB stets neue Tabellen mit neuen Namen angelegt werden. Außerdem ist es hässlich, nun mit zwei Datenbanken zu arbeiten. Schöner wäre es doch, nur mit einer Datenbank auskommen zu können.
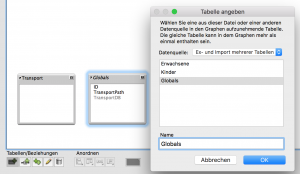
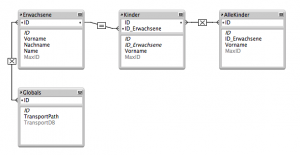 Nun gibt es in FileMaker ja den Feldtyp „Container“, der üblicherweise dafür verwendet wird, Medien (z.B. Bilder oder Videos) in der Datenbank zu halten. So ein Feld kann aber beliebige Dateien aufnehmen, insbesondere auch FileMaker-Datenbanken. Prima, dann erzeugen wir doch ein (globales) Container-Feld „TransportDB“, packen unsere leere Transport-DB dort rein und exportieren diesen Feldinhalt beim Export als FileMaker-Datenbank. Ich verwende für solche System-Globals immer gerne in eine eigene Tabelle, die über Beziehungen mit allen anderen Tabellen verbunden ist, um auf sie von überall aus zugreifen zu können. Damit das gelingt, muss diese Tabelle „Globals“ mindestens einen (leeren) Datensatz enthalten.
Nun gibt es in FileMaker ja den Feldtyp „Container“, der üblicherweise dafür verwendet wird, Medien (z.B. Bilder oder Videos) in der Datenbank zu halten. So ein Feld kann aber beliebige Dateien aufnehmen, insbesondere auch FileMaker-Datenbanken. Prima, dann erzeugen wir doch ein (globales) Container-Feld „TransportDB“, packen unsere leere Transport-DB dort rein und exportieren diesen Feldinhalt beim Export als FileMaker-Datenbank. Ich verwende für solche System-Globals immer gerne in eine eigene Tabelle, die über Beziehungen mit allen anderen Tabellen verbunden ist, um auf sie von überall aus zugreifen zu können. Damit das gelingt, muss diese Tabelle „Globals“ mindestens einen (leeren) Datensatz enthalten.
Das Export-Script in unserer Haupt-DB sieht also so aus:
|
1 2 |
Exportiere alle Feldwerte [ Globals::TransportDB; “file:Transport.fmp12” ] Script ausführen [ “Export” Aus Datei: “Transport” ] |
Zusätzlich können wir vorher noch eine Auswahl der zu exportierenden Datensätze vornehmen, da zum Zeitpunkt des aus Transport-DB-Sicht durchgeführten Imports nur die aktuellen Ergebnismengen herangezogen werden.
Beim Exportieren des Feldinhalts von „TransportDB“ wird eine eventuell aus einem früheren Export vorhandene Transport-DB durch die frische leere Transport-DB überschrieben. Und wir brauchen beim Deployment stets nur unsere Haupt-Datenbank auszuliefern.
So, den Export mehrerer Tabellen in eine Datei haben wir nun geschafft. Wie sieht es mit dem Import aus? Zunächst müssen wir davon ausgehen, den Namen der Datei mit den zu importierenden Tabellen nicht zu kennen. Wir können das also nicht so fest verdrahten wie beim Export; wir müssen beim Import den Benutzer nach der zu importierenden Datenbank fragen. Das bei jeder Tabelle erneut zu tun, ist wieder ausgesprochen hässlich. Auch hier habe ich mir etwas überlegt.
Wir richten in unserer Globals-Tabelle der Haupt-Datenbank ein weiteres globales Textfeld ein, das den Pfad der zu importierenden Datenbank tragen soll. In der Transport-DB erstellen wir ein Script „MyPath“, das in dieses Feld der Haupt-DB den Pfad der geöffneten Transport-DB einträgt:
|
1 |
Feldwert setzen [ Globals::TransportPath; Hole ( DateiPfad ) ] |
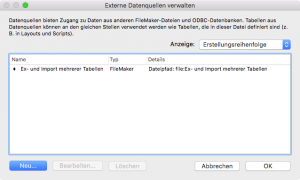 Dafür muss in der Transport-DB die Haupt-DB als externe Datenquelle und die dortige Globals-Tabelle auch im Beziehungsdiagramm eingerichtet werden. Wenn wir nun noch dieses Script automatisch beim Öffnen der Transport-DB ausführen lassen (als Trigger), können wir diesen Pfad beim Import in der Haupt-Datenbank als Quelle eintragen.
Dafür muss in der Transport-DB die Haupt-DB als externe Datenquelle und die dortige Globals-Tabelle auch im Beziehungsdiagramm eingerichtet werden. Wenn wir nun noch dieses Script automatisch beim Öffnen der Transport-DB ausführen lassen (als Trigger), können wir diesen Pfad beim Import in der Haupt-Datenbank als Quelle eintragen.
 Das Import-Script in der Haupt-Datenbank sieht dann so aus:
Das Import-Script in der Haupt-Datenbank sieht dann so aus: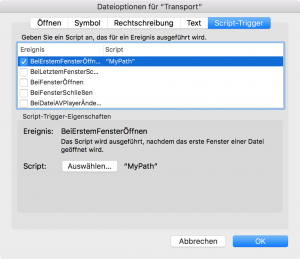
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Eigenes Dialogfeld anzeigen [ Titel: "Achtung"; Mitteilung: "Durch den Import werden alle bisherigen Einträge durch diejenigen der Import-Datei ersetzt! Wollen Sie fortfahren?"; Standardtaste: “OK”, Schreiben: “Ja”; Taste 2: “Abbrechen”, Schreiben: “Nein” ] Wenn [ Hole ( LetzteMeldungswahl ) = 1 ] Datei öffnen [ <Unbekannt> ] [ Ausgeblendet öffnen ] Scriptpause setzen [ Dauer (Sekunden): 1 ] Fenster fixieren Variable setzen [ $Path; Wert:Globals::TransportPath ] Gehe zu Layout [ “Erwachsene” (Erwachsene) ] Alle Datensätze anzeigen Datensätze importieren [ Quelle: “$Path” ODER “file:Transport.fmp12”; Ziel: “Erwachsene”; Methode: Passende aktualisieren; Restliche hinzufügen; Zeichensatz: “Mac Roman”; Feldzuordnung: Quellfeld 1 abgleichen mit Erwachsene::ID Quellfeld 2 importieren in Erwachsene::Vorname Quellfeld 3 importieren in Erwachsene::Nachname ] [ Ohne Dialogfeld ] Gehe zu Layout [ “Kinder” (Kinder) ] Alle Datensätze anzeigen Datensätze importieren [ Quelle: “$Path” ODER “file:Transport.fmp12”; Ziel: “Kinder”; Methode: Passende aktualisieren; Restliche hinzufügen; Zeichensatz: “Mac Roman”; Feldzuordnung: Quellfeld 1 abgleichen mit Kinder::ID Quellfeld 2 importieren in Kinder::Vorname Quellfeld 4 importieren in Kinder::ID_Erwachsene ] [ Ohne Dialogfeld ] Gehe zu Layout [ Originallayout ] Fenster schließen [ Name: Austauschen ( ElementeRechts ( Fensternamen ; 1 ) ; ¶ ; "" ) ] Feldwert setzen [ Globals::TransportPath; "" ] Ende (wenn) |
Zunächst gibt es eine Sicherheitsabfrage, ob wir wirklich die Datensätze in der Haupt-DB überschreiben wollen, wird die positiv beantwortet, lassen wir den Benutzer eine (unbekannte) Transport-DB öffnen. Durch das Öffnen sollte deren „MyPath“-Script ausgeführt werden, das deren Pfad in unser Global-Feld „TransportPath“ einträgt. Wir warten im Script der Haupt-DB besser eine Sekunde, damit das auch zuverlässig erfolgen kann, bevor wir auf dieses Feld zugreifen.
Wir kopieren dieses Feld in die Variable $Path, die bei den folgenden Imports stets als primäre Datenquelle angegeben wird. Zusätzlich haben wir noch eine bereits für den Export benutzte Transport-DB angegeben, um die Tabellen- und Feldzuordnungen beim Import spezifizieren zu können.
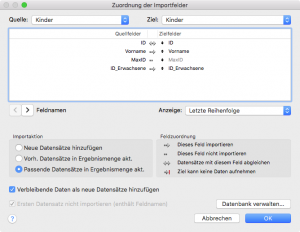 In diesem Beispiel werden die passenden Datensätze in der Haupt-DB aktualisiert (anhand des Schlüssels ID) und die neuen zusätzlichen Datensätze importiert; es werden keine Datensätze in der Haupt-DB gelöscht. Man könnte auch alle bisherigen Datensätze in der Haupt-DB löschen und alle Datensätze aus der Transport-DB importieren; damit würden auch Löschungen in der Haupt-DB möglich.
In diesem Beispiel werden die passenden Datensätze in der Haupt-DB aktualisiert (anhand des Schlüssels ID) und die neuen zusätzlichen Datensätze importiert; es werden keine Datensätze in der Haupt-DB gelöscht. Man könnte auch alle bisherigen Datensätze in der Haupt-DB löschen und alle Datensätze aus der Transport-DB importieren; damit würden auch Löschungen in der Haupt-DB möglich.
Zum Schluss räumen wir noch etwas auf. Wir schließen die zuletzt geöffnete Transport-DB wieder und löschen auch deren Pfad in unserem Global-Feld. Das war’s. Wir haben einen wiederverwendbaren Mechanismus zum Ex- und Import von mehreren Tabellen in und aus einer Transport-Datenbank implementiert. Die Transport-DB kennt die Struktur das betreffenden Tabellen nicht, lediglich die Tabellennamen müssen bekannt sein bzw. ggf. angepasst werden.
Hier ist die Beispiel-Datenbank, auf der dieser Post basiert.